深入解析智慧湿地公园智能问数系统,通过Text-to-SQL技术、自然语言处理、智能图表生成等创新功能,让非技术人员也能轻松完成复杂的数据查询和分析任务,实现数据分析的民主化。
系统核心价值:数据分析的智能化普及
在传统的数据分析模式下,管理人员想要获取一份数据报表,往往需要向IT部门提交需求,等待数据分析师编写SQL语句、导出数据、制作图表,整个流程可能需要数小时甚至数天。更严重的是,管理人员自己无法直接获取数据,必须依赖专业人员,这种"数据壁垒"严重制约了数据价值的释放。
智能问数系统 彻底打破了这一困境。系统基于最新的Text-to-SQL 技术,让管理人员可以用自然语言提出数据查询需求,系统会自动将自然语言转换为SQL查询语句,从数据库中提取数据,并以图表形式展示结果。整个过程不需要编写一行代码,不需要理解数据库结构,就像跟AI聊天一样简单。从"懂技术的人才能查数据"到"会说话就能查数据",这是数据分析领域的一次智能化普及 。
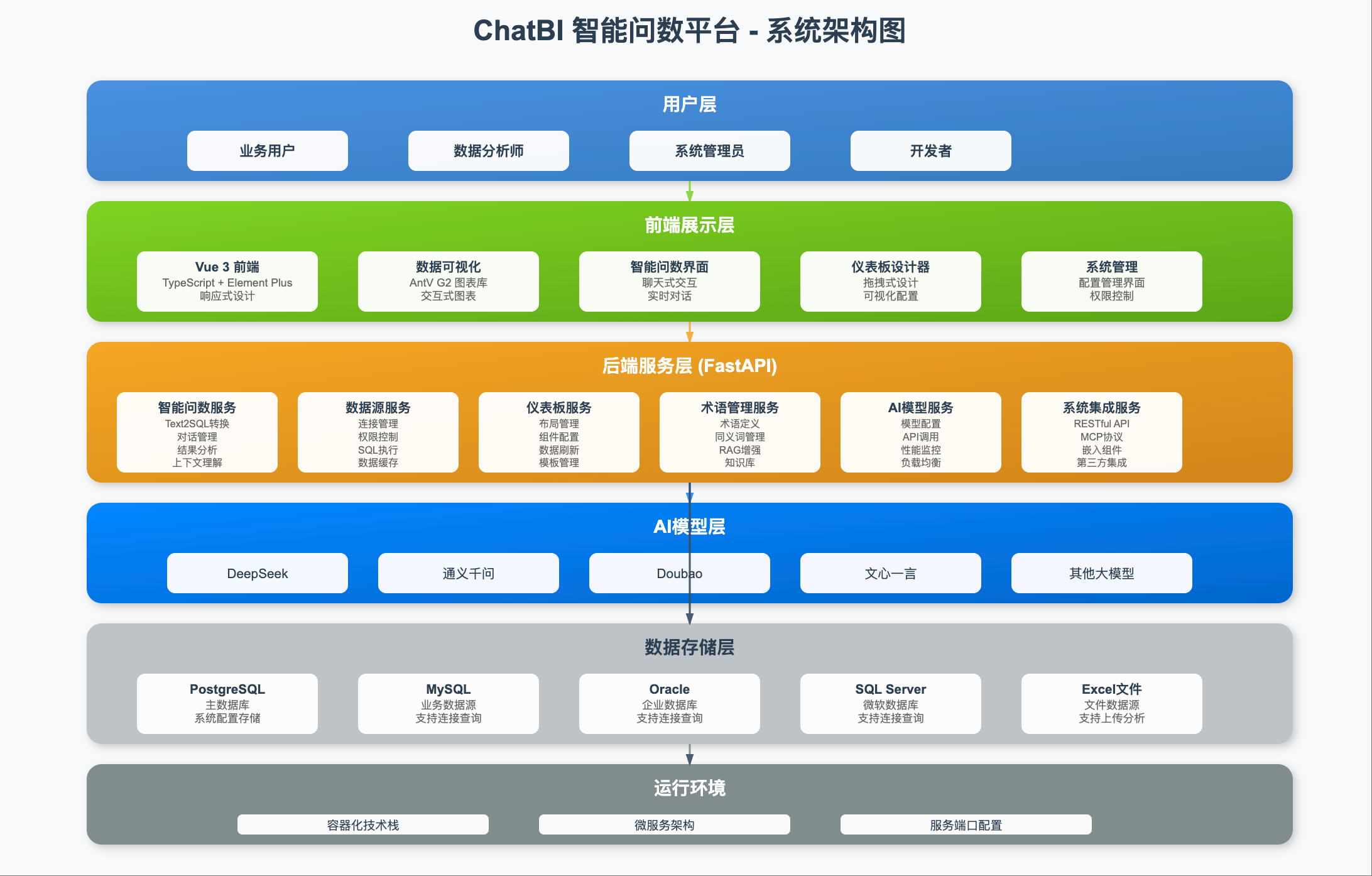
核心功能一:数据源管理 - 多源异构数据的统一接入
数据源管理 是智能问数系统的基础模块。湿地公园的数据分散在多个数据库中:业务数据库存储客流、票务、订单等运营数据,监控数据库存储设备状态、告警记录等物联网数据,日志数据库存储系统操作日志。智能问数系统支持同时对接多个数据源,实现跨库查询和关联分析。
系统支持主流的关系型数据库,包括MySQL、PostgreSQL 等。管理员通过可视化界面配置数据源连接信息(数据库地址、端口、用户名、密码、数据库名称),系统会自动测试连接并导入数据库的表结构元数据 (表名、字段名、字段类型、字段注释、主外键关系等)。这些元数据是后续Text-to-SQL转换的重要依据。
为了保证数据安全,系统支持数据源权限控制 。管理员可以为不同的用户或用户组分配不同的数据源访问权限,例如,普通员工只能访问基础统计数据,管理人员可以访问详细业务数据,高级管理人员可以访问所有数据源。
核心功能二:数据表字段配置 - 让AI理解业务语义
Text-to-SQL技术的核心挑战在于语义理解 。用户用自然语言提问"最近一周的客流量趋势",系统需要理解"客流量"对应数据库中的哪个表、哪个字段,"最近一周"对应什么时间条件,"趋势"需要按日期分组统计。这就需要对数据表和字段进行详细的语义标注。
数据表字段配置 功能提供可视化的语义标注界面。对于每个数据表,管理员可以配置表的业务名称和业务描述 ,例如将"t_visitor_flow"表标注为"游客客流表,记录每日入园离园人数"。对于每个字段,可以配置字段的业务名称、业务含义、单位、取值范围、枚举值映射 等。
例如,"entry_count"字段可以标注为:
- 业务名称:"入园人数、进园人数、客流量"(支持多个同义词)
- 业务含义:"当日进入园区的游客数量"
- 单位:"人"
- 值类型:"整数"
这样,当用户询问"今天的入园人数"或"今日客流量"时,系统都能准确理解为查询"entry_count"字段。
对于枚举字段,语义标注尤为重要。例如,"device_status"字段在数据库中存储为数字编码(1=在线、2=离线、3=故障),但用户提问时会说"在线设备有多少台"而不是"device_status=1的设备有多少台"。通过配置枚举值映射 (1→在线、online、正常),系统就能准确理解用户意图并生成正确的SQL语句。
系统还支持字段关联关系配置 。对于多表关联查询,需要明确表之间的连接条件。例如,"游客订单表"和"景点信息表"通过"景点ID"字段关联,配置好关联关系后,当用户询问"各个景点的订单数量"时,系统能自动生成带JOIN的SQL语句,实现跨表统计。
核心功能三:AI模型配置 - Text-to-SQL的智能引擎
AI模型配置 是智能问数系统的核心技术模块。系统采用大语言模型+Prompt工程 的技术方案,通过精心设计的Prompt引导大模型生成准确的SQL语句。系统支持对接多种大语言模型,包括DeepSeek、通义千问、ChatGLM等。
Prompt设计是影响Text-to-SQL准确率的关键因素。系统的Prompt模板包含以下核心部分:
1. 角色设定 :你是一个专业的SQL工程师,精通数据库查询
2. 任务描述 :根据用户的自然语言问题,生成对应的SQL查询语句
3. 数据库Schema :注入数据表结构、字段含义、枚举映射等元数据
4. 示例演示 :提供若干个"问题→SQL"的示例,引导模型学习转换规则
5. 约束规则 :只返回SQL语句,不要返回解释;使用标准SQL语法;注意日期格式等
6. 用户问题 :用户的实际提问
系统采用Few-Shot Learning 策略,在Prompt中加入典型问题的示例。例如:
问题:"最近7天的客流趋势"
SQL:
SELECT DATE(entry_time) as date, SUM(entry_count) as count FROM t_visitor_flow WHERE entry_time >= DATE_SUB(NOW(), INTERVAL 7 DAY) GROUP BY DATE(entry_time) ORDER BY date
通过学习这些示例,大模型能够更准确地理解问题的意图和生成SQL的规范。
系统还支持SQL语句校验和优化 。生成的SQL语句会先在测试环境中执行验证,如果出现语法错误或逻辑错误,系统会将错误信息反馈给大模型,要求重新生成。对于复杂查询,系统还会进行SQL性能优化,添加必要的索引提示,避免慢查询影响数据库性能。
核心功能四:仪表板配置 - 常用查询的快速复用
虽然智能问数支持随时提问,但对于一些高频查询场景 (如日报数据、周报数据、月度趋势等),每次都重新提问效率不高。仪表板配置 功能允许管理员将常用的查询和图表保存为仪表板,实现快速查看和定期更新。
仪表板支持多种图表类型 :折线图(趋势分析)、柱状图(对比分析)、饼图(占比分析)、散点图(分布分析)、雷达图(多维评估)、表格(明细数据)、数字卡片(关键指标)等。管理员可以通过拖拽的方式调整图表布局,构建个性化的数据看板。
仪表板支持数据自动刷新 。管理员可以设置刷新频率(如每5分钟、每小时、每天),系统会在后台定时执行SQL查询,更新图表数据。对于需要实时监控的指标(如当前在园人数、设备在线率等),可以设置较短的刷新间隔;对于统计类指标(如月度客流、年度收入等),可以设置较长的刷新间隔,避免频繁查询带来的性能开销。
仪表板还支持数据钻取 功能。用户点击图表中的某个数据点,可以查看该数据点的明细信息。例如,在"各区域客流分布"饼图中点击某个区域,会跳转到该区域的客流明细表格,展示每日客流数据。这种交互式的数据探索方式,让数据分析更加直观和深入。
核心功能五:工作空间与权限管理
工作空间管理 提供多租户隔离能力。不同部门或不同业务线可以创建独立的工作空间,每个工作空间有自己的数据源、仪表板、用户权限配置。例如,运营部门的工作空间关注客流、收入、营销数据,技术部门的工作空间关注设备状态、系统性能、日志数据,各个工作空间之间数据隔离、互不干扰。
用户管理 功能提供细粒度的权限控制。系统支持多种用户角色:超级管理员、数据管理员、数据分析师、普通用户 。超级管理员可以管理所有工作空间和用户;数据管理员负责配置数据源和字段语义;数据分析师可以创建和分享仪表板;普通用户只能查看被分享的仪表板和进行简单查询。
嵌入式管理 功能支持将仪表板嵌入到其他系统中。系统提供iframe嵌入代码和API接口,管理员可以将仪表板嵌入到管理平台、小程序、移动App等应用中,实现数据的跨平台展示。嵌入式访问支持单点登录(SSO)和token认证,确保数据安全。
系统设置 模块提供全局配置选项,包括查询超时时间、结果集大小限制、缓存策略、审计日志 等。管理员可以设置单次查询的最大执行时间(如30秒),防止复杂查询长时间占用数据库资源;可以限制查询结果的最大行数(如1万行),避免大数据集导出对系统性能的影响;可以开启查询缓存,对于相同的查询直接返回缓存结果,提升响应速度。
技术实现:从自然语言到SQL的智能转换
Text-to-SQL的技术难点在于自然语言的歧义性 和SQL语法的严谨性 之间的鸿沟。同一个问题可能有多种表达方式,同一个SQL查询也可能有多种写法。系统采用多阶段处理流程 来应对这一挑战:
阶段一:问题预处理。 系统先对用户输入进行预处理,包括同义词替换("客流量"→"入园人数")、时间解析("最近7天"→具体日期范围)、单位标准化("1万人"→"10000")等。预处理后的问题更加规范,降低了大模型理解的难度。
阶段二:Schema检索。 系统不会将所有数据表的Schema都注入Prompt(这会超出Token限制),而是先通过向量检索技术,找出与问题最相关的表和字段。例如,问题是"客流趋势",系统会检索出"游客客流表"及其相关字段,只将这些相关Schema注入Prompt,既保证了信息的完整性,又控制了Prompt的长度。
阶段三:SQL生成。 系统调用大语言模型API,传入精心设计的Prompt,获取生成的SQL语句。为了提高准确率,系统会采用思维链(Chain-of-Thought) 技术,让大模型先分析问题的意图、再确定需要查询的表和字段、最后组装SQL语句,这种"逐步推理"的方式能显著提升复杂查询的准确率。
阶段四:SQL验证与执行。 生成的SQL会先进行语法检查,然后在数据库中执行。如果执行失败,系统会分析错误原因(如表不存在、字段拼写错误、语法错误等),将错误信息反馈给大模型,要求修正SQL。这种"生成-验证-修正"的迭代机制,能够自动纠正大部分错误。
阶段五:结果可视化。 查询结果返回后,系统会根据数据特征自动选择合适的图表类型。例如,时间序列数据自动生成折线图,分类统计数据自动生成柱状图,占比数据自动生成饼图。用户也可以手动切换图表类型,调整图表样式,满足不同的展示需求。
应用价值:从数据壁垒到数据驱动
第一,降低数据分析门槛。 智能问数让数据分析不再是少数技术人员的专利,而是人人都能掌握的技能。管理人员不需要学习SQL语法、不需要理解数据库结构,就能独立完成数据查询和分析。这种能力的下放,让数据真正流动起来,充分释放数据价值。
第二,提升决策响应速度。 传统模式下,从提出数据需求到获得分析结果,可能需要数小时甚至数天。智能问数将这个周期缩短到数秒或数分钟。这种实时性让管理人员能够基于最新数据做出快速决策,抓住稍纵即逝的市场机会。
第三,促进数据探索和创新。 当数据查询变得简单快捷时,管理人员会更愿意尝试各种数据探索。通过不断提问、不断验证,可能发现隐藏在数据背后的规律和洞察,为业务创新提供灵感。数据不再是静态的报表,而是动态的探索工具。
第四,减轻IT部门负担。 传统模式下,大量的数据查询需求挤压IT部门,影响其他重要工作的开展。智能问数让业务人员自助查询,IT部门只需关注数据源配置和系统运维,从繁重的数据提取工作中解放出来,可以投入更多精力到系统优化和技术创新中。